شبکه های اجتماعی
پشتیبانی:9114596785(98+)
شبکه های اجتماعی
پشتیبانی:9114596785(98+)

این مقاله مروری جامع بر کاربردهای هوش مصنوعی در زندگی مدرن ارائه میدهد. از خانههای هوشمند و خودروهای خودران گرفته تا پزشکی دقیق، آموزش شخصیسازی شده و کشاورزی هوشمند، تمام جنبههای این فناوری انقلابی بررسی شده است. همچنین چالشها، فرصتها و آینده هوش مصنوعی مورد تحلیل قرار گرفته تا خوانندگان درک کاملی از تأثیر این فناوری بر زندگی روزمره و آینده بشریت داشته باشند.

هوش مصنوعی با بهرهگیری از دادههای ماهوارهای، حسگرهای هوشمند و الگوریتمهای یادگیری ماشین، ابزارهای قدرتمندی برای نظارت لحظهای، پیشبینی جنگلزدایی، مدیریت کربن و مبارزه با قاچاق چوب ارائه میدهد. این فناوری به حفاظت از جنگلها، کاهش انتشار کربن و بهبود مدیریت منابع طبیعی کمک میکند.

این مقاله به بررسی اهمیت یادگیری زبان برنامهنویسی R برای ورود به حوزه علم داده میپردازد. با تمرکز بر فرصتهای شغلی مانند دانشمند داده، تحلیلگر داده و متخصص هوش تجاری، و کاربرد R در صنایع مختلف از جمله فناوری اطلاعات، مالی، بهداشت و درمان و تجارت الکترونیک، این مقاله نشان میدهد که تسلط بر R سرمایهگذاری راهبردی برای موفقیت در بازار کار رقابتی است. همچنین این مقاله به ویژگیهای متنباز بودن R و جامعه کاربری فعال آن اشاره دارد که تضمینکننده ماندگاری و توسعه این زبان است.
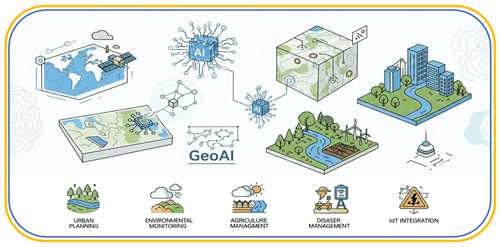
سیستمهای اطلاعات جغرافیایی (GIS) ابزاری کلیدی برای مدیریت و تحلیل دادههای مکانی هستند که در حوزههایی مانند برنامهریزی شهری، کشاورزی، مدیریت بحران و حفاظت از محیطزیست کاربرد دارند. با افزایش حجم و پیچیدگی دادههای مکانی، روشهای سنتی GIS دیگر کافی نیستند. هوش مصنوعی (AI) با قابلیتهای خود در خودکارسازی، شناسایی الگوها و پیشبینی، تحولی عظیم در GIS ایجاد کرده است.

هوش مصنوعی (AI) به سرعت در حال دگرگون کردن جهان ماست و از یک مفهوم علمی-تخیلی به یک واقعیت روزمره تبدیل شده است. این مقاله، به بررسی ابعاد مختلف هوش مصنوعی میپردازد. از تعریف و تاریخچه آن گرفته تا مفاهیم پایه، فناوریها، کاربردها، تأثیرات اجتماعی-اقتصادی، چالشها، ملاحظات اخلاقی و قانونی، و چشمانداز آینده هوش مصنوعی، همگی در این مقاله مورد کاوش قرار میگیرند.

زبان برنامهنویسی R به دلیل قابلیتهای گسترده در تحلیل دادهها و محاسبات آماری، یکی از ابزارهای محبوب در میان پژوهشگران و تحلیلگران داده است. یکی از ویژگیهای کلیدی R، بستهها (Packages) است که امکان گسترش قابلیتهای این زبان را فراهم میکنند. بستهها شامل توابع، دادهها و مستنداتی هستند که برای انجام وظایف خاص طراحی شدهاند.با استفاده از مخازن معتبر و مدیریت صحیح بستهها، میتوان بهرهوری خود را در پروژههای تحلیلی افزایش داد.
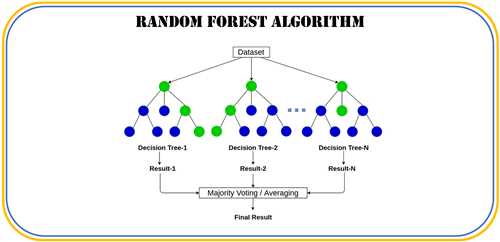
الگوریتم جنگل تصادفی یکی از روشهای محبوب و قدرتمند در یادگیری ماشین است که با ترکیب چندین درخت تصمیم و استفاده از اصول تصادفیسازی، دقت و پایداری مدل را افزایش میدهد. این الگوریتم از سه اصل اصلی نمونهگیری تصادفی از دادهها، انتخاب تصادفی ویژگیها، و ترکیب نتایج درختها استفاده میکند تا مشکلات رایج مانند بیشبرازش را کاهش دهد. ا این حال، چالشهایی مانند سرعت پایین در دادههای بزرگ، دشواری تفسیر نتایج، و نیاز به تنظیم دقیق پارامترها از محدودیتهای آن محسوب میشوند.
آدرس:مازندران،نور، بلوار امام رضا، پردیس منابع طبیعی و علوم دریایی دانشگاه تربیت مدرس
تلفن تماس:01144998066
ارتباط با مدیریت سایت:09045271357