شبکه های اجتماعی
پشتیبانی:9114596785(98+)
شبکه های اجتماعی
پشتیبانی:9114596785(98+)

این مقاله مروری جامع بر کاربردهای هوش مصنوعی در زندگی مدرن ارائه میدهد. از خانههای هوشمند و خودروهای خودران گرفته تا پزشکی دقیق، آموزش شخصیسازی شده و کشاورزی هوشمند، تمام جنبههای این فناوری انقلابی بررسی شده است. همچنین چالشها، فرصتها و آینده هوش مصنوعی مورد تحلیل قرار گرفته تا خوانندگان درک کاملی از تأثیر این فناوری بر زندگی روزمره و آینده بشریت داشته باشند.

توقف بهرهبرداری از جنگلهای شمالی ایران، با عنوان «طرح تنفس»، تصمیمی بزرگ و بحثبرانگیز بود. اما آیا حذف ناگهانی بهرهبرداری بدون جایگزین مدیریتی، به نجات جنگلها کمک کرده یا آنها را بیدفاعتر از همیشه رها کرده است؟
توقف بهرهبرداری از جنگلهای شمالی ایران، با عنوان «طرح تنفس»، تصمیمی بزرگ و بحثبرانگیز بود. اما آیا حذف ناگهانی بهرهبرداری بدون جایگزین مدیریتی، به نجات جنگلها کمک کرده یا آنها را بیدفاعتر از همیشه رها کرده است؟

سال 2024 با ثبت دمای جهانی 1.5 درجه سانتیگراد بالاتر از دوره پیشصنعتی، بهعنوان گرمترین سال تاریخ ثبت شد. سرویس تغییرات اقلیمی کپرنیکوس گزارش داد که انتشار دیاکسید کربن از سوختهای فسیلی باعث خشکسالیهای شدید در ایتالیا و آمریکای جنوبی، سیلهای مرگبار در نپال، سودان و اروپا، موجهای گرمایی کشنده در مکزیک و عربستان، و طوفانهای ویرانگر در آمریکا و فیلیپین شده است. مطالعات علمی نقش فعالیتهای انسانی را در این بلایا تأیید میکنند. کاهش سوختهای فسیلی و حمایت از کشورهای آسیبپذیر ضروری است.

هوش مصنوعی با بهرهگیری از دادههای ماهوارهای، حسگرهای هوشمند و الگوریتمهای یادگیری ماشین، ابزارهای قدرتمندی برای نظارت لحظهای، پیشبینی جنگلزدایی، مدیریت کربن و مبارزه با قاچاق چوب ارائه میدهد. این فناوری به حفاظت از جنگلها، کاهش انتشار کربن و بهبود مدیریت منابع طبیعی کمک میکند.

این مقاله به بررسی اهمیت یادگیری زبان برنامهنویسی R برای ورود به حوزه علم داده میپردازد. با تمرکز بر فرصتهای شغلی مانند دانشمند داده، تحلیلگر داده و متخصص هوش تجاری، و کاربرد R در صنایع مختلف از جمله فناوری اطلاعات، مالی، بهداشت و درمان و تجارت الکترونیک، این مقاله نشان میدهد که تسلط بر R سرمایهگذاری راهبردی برای موفقیت در بازار کار رقابتی است. همچنین این مقاله به ویژگیهای متنباز بودن R و جامعه کاربری فعال آن اشاره دارد که تضمینکننده ماندگاری و توسعه این زبان است.
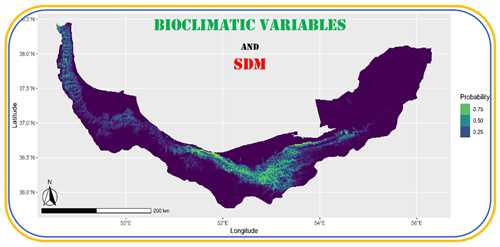
متغیرهای زیستاقلیمی ابزارهایی کلیدی برای تحلیل اقلیمی و مدلسازی پراکنش گونهها هستند. این مقاله 19 متغیر زیست اقلیمی را در چهار دسته بررسی کرده و کاربرد آنها در حفاظت تنوع زیستی، مدیریت اکوسیستم و پیشبینی اثرات تغییرات اقلیمی را توضیح میدهد.
آدرس:مازندران،نور، بلوار امام رضا، پردیس منابع طبیعی و علوم دریایی دانشگاه تربیت مدرس
تلفن تماس:01144998066
ارتباط با مدیریت سایت:09045271357